Business Analytics กับการใช้ CRISP-DM แก้ปัญหา
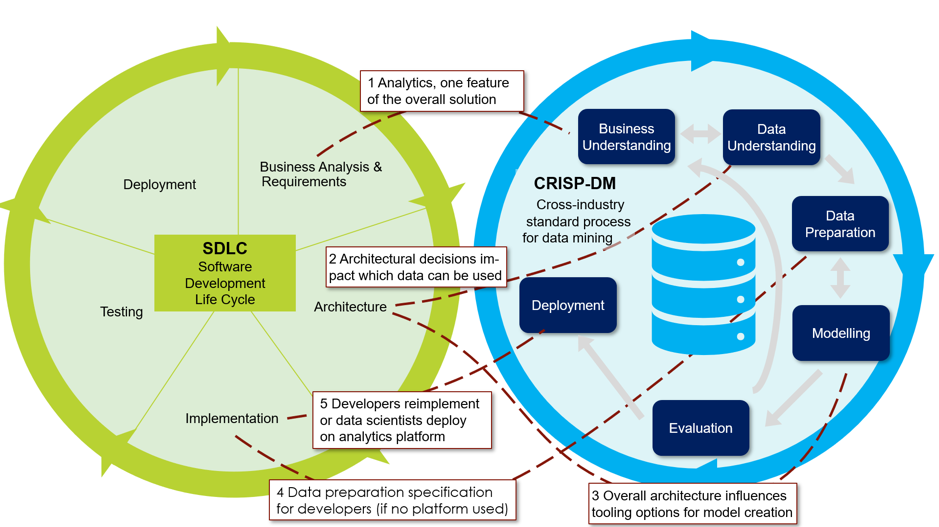
CRISP-DM ย่อมาจาก Cross-Industry Standard Process for Data Mining เป็นกระบวนการในการจัดทำเหมืองข้อมูลเพื่อการวิเคราห์และใช้ประโยชน์ทางธุรกิจซึ่งประกอบด้วย 6 ขั้นตอนหลักด้วยกัน ได้แก่
- Business Understanding – ก็คือการเข้าใจธุรกิจ หรือโจทย์นั้นๆที่ได้ตั้งไว้โดยเริ่มจากการตั้งเป้าหมายของโจทย์ว่าเราต้องการเป้าหมายอะไร และต้องกำหนดตัววัดผลที่ดีและชัดเจนเพื่อจะได้รู้ว่าเราทำได้ตามเป้าหมายขนาดไหน
- Data Understanding – คือการเข้าใจชุดข้อมูลที่เราได้นำมาวิเคราะห์อย่างจริงๆจังๆ โดยมีการอ้างอิงจาก Garbage In Garbage Out Model ว่า ถ้าหากเรามีชุดข้อมูลที่ดีมากๆ แต่เมื่อเราเอาชุดข้อมูลไปทำ model แล้ว model นั้นไม่เกิดประโยชน์ หรือ เรามี modelแนวความคิดที่ดีมากๆ แต่มีชุดข้อมูลที่ไม่มีประโยชน์และไม่ได้เรื่องเลย สุดท้ายแล้วก็ก่อเกิดเป็นขยะนั้นเอง
- Data Preparation – คือขั้นตอนการเตรียมข้อมูลก่อนนำไปใช้ซึ่งจะประกอบไปด้วย 3 ขั้นตอนใหญ่ๆคือ Cleaning/ Integration คือการลดทอนข้อมูลที่ไม่มีคุณภาพ, Transformation คือการแปลงข้อมูลให้พร้อมใช้งาน และ Partition คือขั้นตอนการแบ่งข้อมูล โดยใช้ Supervised Learning Model
- Modeling Training Dataset – คือขั้นตอนการเตรียมข้อมูลเสร็จแล้วและลองนำข้อมูลนั้นมาทำ Decision Tree หรือ Logistic Regression เพื่อดูความน่าจะเป็นของชุดข้อมูล
- Evaluation Testing Dataset – เป็นการคำนวนเพื่อดูความเป็นไปได้ของชุดข้อมูล
- Deployment – เป็นการนำข้อมูลทั้งหมดจากที่เราสรุปมานำไปใช้ โดยเราจะมีข้อมูลเป็น 3 ชุดใหญ่ๆอยู่แล้วคือ Final Report คือรายงานที่เอาให้ทีมผู้บริหารดูซึ่งก็คือผลที่ได้จากการทำ model แล้วเราจึงมีรายงาน Monitoring เพื่อให้ทีมผู้บริหารตัดสินใจว่าจะใช้ model นี้ไหม แล้วสุดท้ายก็จะมี รายงาน Plan ว่าอนาคตจะเป็นยังไงต่อ
สำหรับท่านที่ต้องการทำ แอพ E-Commerce , App ช้อปปิ้ง หรือ แอพ Delivery แล้วล่ะก็ เราขอแนะนำ บริษัท SC-Spark Solution บริษัท รับทำแอป เป็นบริษัทที่รับทำแอพพลิเคชั่น ที่มากประสบการณ์ โดยมีประสบกาณ์โดยตรงจาก Silicon Valley เป็นบริษัทผู้พัฒนาแอปพลิเคชั่นมากกว่า 100 บริษัททั่วโลก ทั้งแบบ Custom และ สำเร็จรูปให้คุณได้เลือกใช้ หากใครสนใจ บริการทำโมบายแอพพลิเคชั่น หรือ เว็บไซต์ สามารถติดต่อได้ที่นี่
ติดต่อเราได้ที่
Facebook : SC-Spark Solution บริการทำแอปพลิเคชั่น
“Nothing is impossible”




